
DB 부하 분산을 위한 캐시 적용
왜 Cache를 사용하게 되었는가?
로그인과 회원 관리 기능을 구축한 후 본격적으로 게임 목록을 가져오는 로직 구축을 시작했습니다. 해당 기능은 사용자가 로그인하면 db에 저장되어 있는 게임 리스트를 가져와 보여줍니다. 제 서비스는 수 천명의 사용자가 동시에 여러 게임 데이터를 조회한다는 가정 하에 작성하고 있습니다. 잦은 게임 리스트 호출은 디스크 IO 발생과 네트워크 사용으로 트래픽 성능 저하가 일어날 수 있습니다. 사용자들은 몇 초의 로딩 시간에도 불만을 가질 수 있는데 만약 대기 시간이 길어진다면 더 나은 환경의 게임 사이트를 찾아 떠날 겁니다.
최대한 로딩 시간을 줄이면서 서버에 부하를 주지 않을 방법을 찾아야 했습니다. MySQL의 경우 scale up만 가능해 성능 확장에 한계가 있고 무엇보다 하나의 서버에 부하가 집중돼 근본적인 해결책이 되지 못합니다. 그래서 DB 부하 분산 방법을 찾다 캐싱이라는 방식을 발견했습니다.
Cache란?
MySQL 같은 디스크 저장소에서 데이터를 불러오려면 네트워크를 타고 접근해 쿼리를 파싱하는 등 복잡한 연산이 생깁니다. 캐시는 고속 저장소로 대용량 데이터, 복잡한 수학적 연산 결과, 정적 컨텐츠 등을 연산 없이 데이터를 불러올 수 있어 CPU 기능 부하와 지연 시간을 줄여줄 수 있고 퍼포먼스를 향상 시킬 수 있습니다. 보통 RAM이나 인메모리 엔진 같이 가볍고 빠른 하드웨어에 설치되어 실행됩니다.
위 특징만 본다면 느린 디스크 대신 캐시만 활용하는게 효율적으로 보일 수 있지만 캐시 히트율과 인메모리 db 특징에 대해서 좀 더 살펴본 다음 결정해보기로 했습니다.
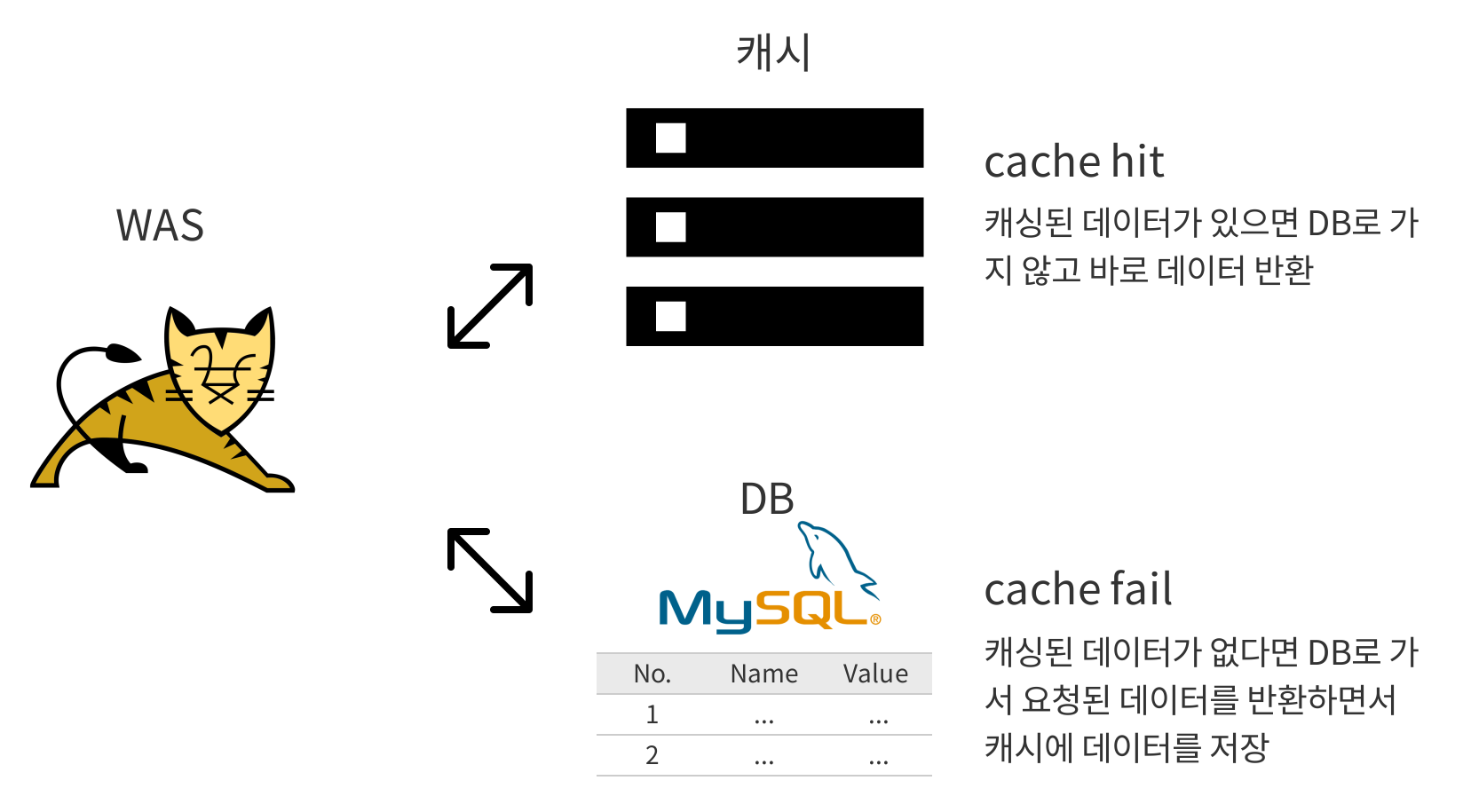
캐시 히트율(cache hit rate)은 요청이 들어왔을 때 캐싱된 데이터가 있는 확률로 들어온 전체 요청 수 대비 캐시가 히트돼서 응답한 개수를 나타냅니다. 캐시 히트율이 높다는 건 그만큼 캐싱 데이터가 쓰여서 성능이 높다는 걸 의미합니다. 하지만 무조건 높다는 게 좋은 건 아닙니다. RDB인 MySQL과 캐시 DB인 Redis는 실시간 싱크(synch)가 이뤄지지 않기에 즉각적인 데이터 반영이 필요한 경우 캐시 사용이 적합하지 않습니다. @CachePut과 @CacheEvict를 사용해 캐시의 UPDATE나 DELETE가 가능하지만 프로세스 중 변경된 데이터가 반영되는 시간 차이는 여전히 존재합니다.
때문에 데이터 일관성을 위해서 TTL(Time To Live)을 이용해 일정 시간이 지나면 캐시를 소멸하고 다음 요청 때 db에서 가져온 값을 저장해 주기적으로 업데이트할 수 있습니다. 또한 캐시는 휘발성 저장소입니다. 높은 IOPS(Input/Output Operations Per Second)을 가져 요청에 대한 입출력이 빠르게 진행되지만 예기치 않은 에러로 종료가 된다면 데이터는 삭제됩니다. 그러기에 데이터의 일관성과 안정성을 위해서 디스크 db와 캐시를 함께 사용하는 경우가 많습니다.
로컬 캐시와 글로벌 캐시
캐싱 타입은 여러 종류가 있지만 그 중에서 자주 언급되는 로컬 캐시(local cache)와 글로벌 캐시(distributed cache)에 대해 알아보겠습니다.
로컬 캐시는 애플리케이션 메모리 안에 캐싱한 데이터를 보관하는 저장소입니다. 저장 가능한 용량은 크지 않지만 로컬에서 빠르게 접근이 가능해 지연 시간을 줄일 수 있습니다. 대신 여러 애플리케이션을 동시에 사용할 때 저장소 간 데이터 일치성을 가지기 어렵고 네트워크 비용이 발생합니다. 이런 특징은 작은 크기의 데이터를 호출하는 싱글 어플리케이션 서비스에 적합합니다.
글로벌 캐시는 두 개 이상의 애플리케이션이 공통된 캐시 저장소를 가집니다. 저장소 크기는 로컬 캐시보다 크기에 데이터를 더 많이 보관할 수 있지만 애플리케이션 바깥에 위치해 있기에 접근 속도는 비교적 느립니다. 여러 어플리케이션이 동일한 데이터를 가져야 하는 서비스에 사용되면 효과적입니다.
Redis vs. Memcached
캐시용 인메모리 db를 찾게 되면 가장 많이 마주하는 게 Redis와 Memcached입니다. 두 기능 모두 NoSQL 형식으로 키-값 형태를 이룹니다. 현재 제가 사용하고 있는 자바 언어의 클라이언트를 제공하며 Memcached는 Xmemcached과 Memcached-java-client를 제공하고 Redis는 Jedis, Lettuce, Redisson을 제공합니다.
언뜻 보기에는 비슷해 보이지만 차이점이 여럿 있습니다.
데이터 자료형과 그에 따른 메모리 사용량
Memcached는 key와 value가 String 자료형으로 최대 1MB까지 저장합니다. Redis는 5개의 데이터 자료형(String, Hash, List, Set, Sorted set)을 사용하며 키와 값 모두 512MB까지 저장 가능합니다. String으로만 구성된 Memcached는 일반적으로 Redis보다 빠르지만 Redis의 Hash로 직렬화, 역직렬화 과정을 거치지 않고 객체를 저장할 수 있어 애플리케이션 개발이 수월해지고 IO 과정이 줄어 들어 효율적입니다.
구조와 확장법
Memcached는 멀티 코어 구조로 된 멀티 쓰레드를 지원합니다. 따라서 용량을 늘리려면 코어나 쓰레드를 추가하는 수평멀티 쓰레드를 지원합니다. 따라서 용량을 늘리려면 코어나 쓰레드를 추가하는 수평적 확장이 가능합니다. 큰 데이터셋을 다뤄야 하는 경우 Redis보다 더 빠른 성능을 보입니다. 그에 비해 Redis는 싱글 쓰레드 구조이며 수평적, 수직적 확장 둘 다 가능합니다. 수평적 확장의 경우 노드 그룹(샤드) 개수를 조정하면 되고, 수직적 확장은 노드의 클러스터 크기를 늘리면 됩니다.
데이터 영속성
데이터 영속성(data persistence)은 데이터를 생성했던 애플리케이션이 종료되도 데이터가 휘발되지 않고 계속 남아있는 특성을 의미합니다. 영속성이 유지되려면 가변적(volatile)이지 않은 데이터베이스에 담겨져야 합니다. Memcached는 인메모리 캐시로 휘발성 데이터를 가지게 되어 Memcached가 종료되면 그동안 저장됐던 데이터는 사라지게 됩니다. 반면 Redis는 완전한 인메모리가 아닌 데이터 스토어로 데이터를 유지할 수 있는 방법이 두 가지가 있습니다.
먼저, RDB snapshot는 특정 시간에 모든 데이터셋을 스냅샷으로 찍어 디스크 내에 있는 파일에 저장하는 기능입니다. 복원할 데이터 양이 많아질 수록 응답 시간이 길어지는 특징이 있습니다. 두번째로 AOF(Append-Only File) log는 레디스 서버에서 수행된 모든 쓰기 기능을 기록하며 디스크에 순서대로 적습니다. 서버가 에러가 나도 로그 내용을 그대로 수행하면 데이터를 복원할 수 있습니다. 파일에 append 명령어로 이어 붙여서 데이터가 변질될 가능성은 없지만 레디스가 계속 켜져있으면 RDB보다 저장할 데이터가 훨씬 빨리 증가합니다.
캐시는 임시 저장소로 사용할 거라 데이터 영속성은 논외 대상입니다.
데이터 이빅션(Data Eviction)에 대한 알고리즘
데이터 이빅션은 메모리에 여유 공간이 없을 때 축출 대상의 우선 순위를 정하는 방법입니다. Memcached는 가장 오랫동안 사용되지 않은 데이터를 축출하는 LRU(Least Recently Used) 정책만 지원되지만 Redis는 8가지 정책 중 고를 수 있습니다.
| 알고리즘 | 방식 |
|---|---|
| noeviction | 메모리가 다 찬 경우 에러 표시 |
| allkeys-LRU | 가장 사용되지 않은 데이터 축출 |
| volatile-LRU | 가장 사용되지 않음 + 만료 기간 설정 |
| allkeys-random | 랜덤하게 축출 |
| volatile-random | 랜덤 + 만료 기간 축출 |
| volatile-TTL | 제일 짧은 TTL + 만료 기간 설정 |
| volatile-lfu | 제일 사용되지 않음 + 만료 기간 설정(Redis 4.0부터 추가) |
| allkeys-lfu | 제일 사용되지 않는 데이터 축출(Redis 4.0부터 추가) |
출처 : https://redis.io/topics/lru-cache
트랜젝션
Memcached는 원자성은 있지만 트랜잭션을 제공하지 않는 반면 Redis는 트랜잭션 기능을 제공합니다. 여기서 원자성은 트랜잭션의 4가지 특성인 ACID 중 원자성(atomicity)을 뜻합니다. 원자는 물질의 가장 최소 단위로 더 이상 쪼갤 수 없는 상태를 뜻하는 만큼 원자성은 작업 단위를 하나로 인식해 전부 commit이 되거나 rollback이 되는 기능을 의미합니다. Memcached는 멀티 쓰레드 구조로 여러 쓰레드가 한 번에 동일한 트랜잭션 기능에 접근하게 되면 원자성을 보장한다 해도 다른 쓰레드의 값으로 겹쳐질 수 있는 위험이 있습니다.
아래 문장은 Memcached 문서에서 발췌한 내용입니다.
A series of commands is not atomic. If you issue a ‘get’ against an item, operate on the data, then wish to ‘set’ it back into memcached, you are not guaranteed to be the only process working on that value. In parallel, you could end up overwriting a value set by something else.
선택
Cache를 적용하기 위해 Redis를 사용하기로 했습니다.
- 이미 세션 분산 이슈로 Redis를 가동 중이라 기능 추가만 하면 됨
- Spring에서는 3.1 버전부터 cache를 기존에 있던 스프링 애플리케이션에 코드 변화 없이 적용 가능
- 데이터 저장 시 다양한 자료형을 지원
- IO 횟수 감소
적용
먼저 Redis 캐시를 적용하기 위해 CacheManger를 configure 해줘야 합니다. 제 경우는 게임 리스트를 별도로 캐시하기 위해 Map 객체를 선언해 그 안에 GAME_LIST라는 키값과 5초 후에 캐싱 데이터를 삭제하는 entryTtl을 지정해줬습니다.
@Bean
public RedisCacheManager redisCacheManager(RedisConnectionFactory redisConnectionFactory) {
RedisCacheConfiguration redisCacheConfiguration = RedisCacheConfiguration
.defaultCacheConfig()
.disableCachingNullValues()
.serializeKeysWith(RedisSerializationContext
.SerializationPair
.fromSerializer(new StringRedisSerializer()))
.serializeValuesWith(RedisSerializationContext
.SerializationPair
.fromSerializer(new GenericJackson2JsonRedisSerializer()));
Map<String, RedisCacheConfiguration> cacheConfiguration = new HashMap<>();
cacheConfiguration.put(GAME_LIST, redisCacheConfiguration.entryTtl(Duration.ofSeconds(5)));
return RedisCacheManager
.RedisCacheManagerBuilder
.fromConnectionFactory(redisConnectionFactory)
.cacheDefaults(redisCacheConfiguration)
.build();
}
Configuration이 끝나면 캐시를 사용하고 싶은 메서드에 @Cacheable을 사용하면 첫 요청 시에 디스크에서 가져온 데이터를 캐시에 저장합니다. 그러면 다음 호출부터는 저장된 데이터를 그대로 불러옵니다. Redis는 키-값 형태로 데이터를 저장하기에 키를 argument로 받는 listInfo로 지정하고, 값은 GAME_LIST 키를 찾아 가져오게 합니다.
@Cacheable(key = "#listInfo", value = GAME_LIST, cacheManager = "redisCacheManager")
@LoginCheck(authLevel = AuthLevel.USER)
@GetMapping("/")
public List<GameDto> selectGameList(GamePagingDto listInfo) {
return gameService.getGameList(listInfo);
}
마치며
지금까지 긴 글 읽어주셔서 감사합니다.
위 내용을 적용한 프로젝트는 여기에서 볼 수 있습니다.
아직 갈 길이 먼 프로젝트이나, 조금씩 진행되고 있으니 생각나면 간간이 들러주세요.

출처
- https://docs.spring.io/spring-framework/docs/current/reference/html/integration.html#cache
- https://aws.amazon.com/caching/?nc1=h_ls
- https://www.imaginarycloud.com/blog/redis-vs-memcached/
- https://www.baeldung.com/memcached-vs-redis
- https://docs.oracle.com/cd/E18686_01/coh.37/e18677/cache_intro.htm#COHDG320
- https://docs.aws.amazon.com/AmazonElastiCache/latest/red-ug/scaling-redis-cluster-mode-enabled.html
Comments